
Or was there even a war?
But before we dive into the title subject, a brief refresh of history.
I clearly remember the first time I saw a Linux prompt. My friend and classmate in our second year of college came and grabbed me to come look at his PC. “Check this out!” “Oh, you are logged in to the lab?” “No, I installed Linux”. I think he had just installed an early version of Slackware Linux.
To the nerds the sight of a small $ prompt sitting stoically on that boring 80x25 black background text mode display – at the time – seemed immensely remarkable. Because the power behind that simple prompt, was immense. We had experience on the SunOS boxes in the computer science department, but the idea you could have this on your PC was astonishing.
It was 1995. And Windows Server had yet to even be. NT 4.0 came out the next year. And for almost a decade Windows overshadowed Linux in the server space. But behind the scenes Linux was planting the seeds, seeds which would eventually put it almost everywhere.

In the late 90s / early 2000s building highly scalable systems that could span many pieces of commodity hardware was a problem only Internet scale companies and startups worried about. Or the few folks building Beowulf super-computer clusters. They were custom pieces of software, built often from the ground up for a very specific purpose – and highly proprietary.
Instead, most enterprises got their scalability from using higher-end hardware, and fancy licensed software such as DB2 or Oracle which supported a specific and proprietary way of scaling. Storage scaled by using large RAID systems or incredibly expensive SAN solutions. And for many enterprises, this is still the way it is.
In 2003 Google released a research paper on the Google File System1 and then followed it up with one on MapReduce in 20042. These papers opened a lot of developer’s eyes to what well-built commodity clusters could do. And projects like Hadoop and Cassandra followed. Soon there were good ways to store data at potentially limitless scale, basically as key value pairs.
But how do you scale the applications themselves? And how do you scale applications in a standard way – a method that everyone agrees is the way to scale.
It’s a HARD question. A question a lot of professors, PhDs, developers, startups and incumbent huge companies have tried to answer over many decades with products and standards. It’s still a hard problem.
But before we go there… Where did “containers” come from? Because containers are critical to scaling applications today.
Containers Are Not New
OS Containers are not a new thing at all. Containers evolved as pragmatic solutions to real challenges as the Internet quickly grew.
The chroot() system call was in Unix as early as 1979. That chroot’s concept and a lot of others are needed to create the walls of the “container” for an application. For those that don’t know, chroot basically makes it so a process can only see part of the filesystem on the machine – i.e. it gets a window to see part of the house, if you will. chroot() was first used to assist in the development of Unix itself – but its use as a security measure was quickly realized – known colloquially as a “chroot jail”. There is even a paper in 1991 from Bill Cheswick at Bell Labs where he uses chroot to honeypot a network intruder, showing the early security value of a container.3
FreeBSD Jails
Before containers surfaced as we know them today, there were a lot of forerunners in the early 2000s. FreeBSD jails came out in 2000 – built again, from pragmatic needs. A shop in South Carolina needed the ability to run different versions of web server software for different customers on the same host. The company actually paid for the development of the feature, and then a year later it made its way into FreeBSD 4. Kamp, the author, discusses it here in a Youtube video (15 min in)
Virtuozzo & OpenVZ
The needs of web hosting shops continued to drive container development for a while. Virtuozzo, introduced in 2001, is a Linux based platform used by many service providers, ISVs and PaaS companies. It along with OpenVZ, the core virtualization engine of Virtuozzo – released separately a few years later, opened the eyes of possibility across the Linux community.
Cgroups
In 2007 the Linux kernel got “cgroups” which is a low-level feature that imparts a lot more power to container systems. It was largely developed and pushed by Google.4 The cgroups kernel additions along with existing features such as namespace and features mainlined from SELinux enabled containers to have a lot of the same features complete VM systems like Xen and KVM or even VMWare had. Examples being hard CPU and disk resource limits.
Just as important, Linux containers designed using cgroup features could scale way better on hardware, because they did not require the entire OS and it’s kernel to be loaded in memory. But cgroups are a kernel feature, not a product to build and run containers. And while these features were immediately used by sophisticated developers at places like Google, many Linux users lacked the time and expertise to leverage them.

LXC
LXC arrived on the scene in 2008. LXC had userspace tools to create containers. In fact, you could run a whole new Linux OS in a container, without using a VM. One of the big advantages of LXC was that it worked in the mainline kernel. It took advantage of newer Linux kernel features.
LXC, and now LXD, are actively developed and overseen by Canonical. They should really be thought of as a set of powerful tools to do “container things” In fact, early versions of Docker used LXC to drive container setup.
Docker
Which takes us to Docker. Released in 2013, Docker’s real innovation wasn’t a container – it was the developer experience. Suddenly it became somewhat easy and manageable to create a “container image”, save that image to a “registry”, and “pull” it and run it when you liked. Docker’s relative ease of use, versus the more complicated if not powerful capabilities of systems like LXC or Virtuozzo, was the key factor that was needed take containers mainstream.

Docker suddenly made containers hot - red hot. And it did the same for Docker, the company. Starting off as dotCloud in 2008, which was building a PaaS product to create, package and deploy applications. As part of this effort, the company created a tool to make containers. In 2013, the company decided to open-source that tool as Docker.5 The decision changed the company – and docker suddenly turned Docker into a serious big-deal in Silicon Valley. So much so the company changed its name to “Docker Inc.”6 By 2015, Docker was considered a unicorn, with a valuation above $1B.7
It was Docker everywhere. They even started their own conference - DockerCon - in 2014, with huge names and sponsors attending. And reporters on blogs like Venturebeat and Techcrunch, who had not a clue what a container was a year or two before, were covering it live as if it was an Apple event.
The unfortunate fate of Docker as a company could be a whole separate discussion best explained by those who were part of it. A worthwhile read is Scott Carey’s article in InfoWorld from 2021 - but Docker the tool’s role in allowing anyone to produce a container image was critical. As time has moved on, containers now have a standard, Open Container Initiative (OCI) - which Docker Inc. helped establish, and a variety of OCI-compatible runtimes exist.
Let’s Scale

Google is a huge hardware company. Many people fail to fully recognize this. In fact, by some publicly available measures, Google operates more data center hardware than any other hyper-scaler. Google is also a massive network operator, having built out not just consumer-facing services like Google Fiber, but even laying down major transocean cables.8 In some places, it really is the Internet.
This is because Google needs massive scale and speed for search and its tangential services. But, in fact, Google was always a hardware company, a custom server manufacturer in a sense. In fact, the key innovation for Google’s search, in the very earliest days was breaking up the problem of search into a problem that could be spread across simple commodity PCs. And they quickly learned to bring these PCs down to their bare necessities for scale and cost efficiency.
The fact that scale could be achieved by simply adding machines with relatively inexpensive x86 hardware, was critical to the company’s early success. And building services this way meant that Google benefited strongly as the market prices of compute and memory dropped.
As documented in David Vise’s “Google Story” from 2005, Andy Bechtolsheim, the co-founder of Sun Microsystems wrote the first investment check to “Google Inc” before Google Inc even existed. He was convinced by the scalability pitch that Sergey and Brin gave him. When Andy asked them what they would do with money, the guys had a simple answer: buy hardware to build machines.
So part of the core DNA of Google was the engineering concept of scalability. Serious, almost limitless scalability. Massive, web-scale scalability. At the time no one had ever scaled a service like this - not this big.
With that in mind, it should come as no surprise that as Google grew it ended up building arguably the world’s most advanced server and application management system. A system known as “Borg.”
Borg: the Forefather of Kubernetes
Kubernetes was released in 2015. This same year Google released a paper on Borg – and a blog entry on the Kubernetes site explaining that Borg was the forefather of Kubernetes.9 Kubernetes billed itself as “container cluster management.”10 Today we broadly call this “container orchestration.” The community quickly started using “K8s” as the Kubernetes short name.
The Hard Problem of Scaling in a Common Way
Let’s go back to the hard question: How do you scale applications in a vendor-independent way? Put another way – what is a framework that almost all development teams can use to make their apps more reliable and scalable?
By 2013, the year docker came on the scene a variety of container orchestration systems existed. For a moment, a brief review of what “orchestration” really means.
Microservices
Microservices are a way of making applications by breaking them down into a set of small services, some of which communicate to the end user, often by answering an HTTP API call, others which may do backend work such as analyze data, or store it to a database. The services communicate with one another to create the overall application.
Microservices are a form of Service Oriented Architecture, or SOA, which has its origins from the late 90’s with Open Group, an early consortium of a bunch of big players in the Unix server and workstation space.
By the beginning of the 2010s “microservice” was emerging as a new buzzword, and developers were beginning to think about how to design new applications as a set of microservices.
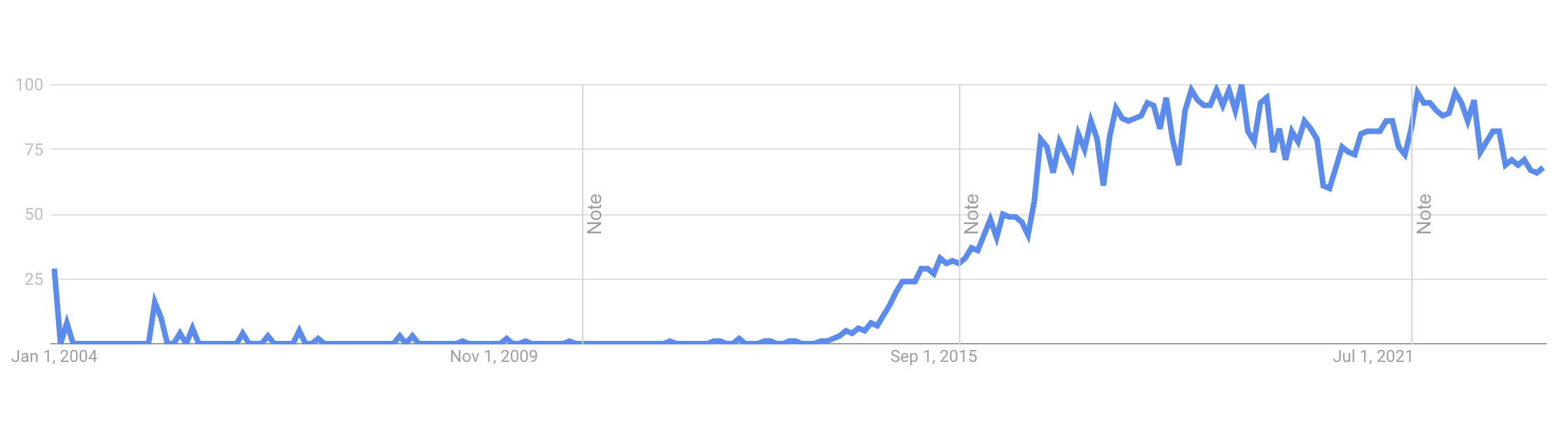
When you break an application down into smaller services, it provides the opportunity to also run multiple copies of each service for added reliability. Granted this requires your software to be designed in a way to handle multiple instances of these small services, be stateless, use persistent queues, etc – and there are many tools for helping do this (RabbitMQ, Kafka, various other services busses and now “service meshes”) and of course many people have strong opinions on which methods to use. There are, of course, other things to consider: how do you distribute traffic across these services, how do you find the services, and so forth. However you do it, it means that your application can result in higher reliability and scale larger as needed. The system can add more containers of this and that as needed, and restart ones that fail.
That’s application orchestration. You can find much more complicated definitions. But basically, it’s a way of ensuring your services, which make up your application, deploy in a certain way so they can work together and recover from outages, so the entire application runs reliably and scales easier.
It turns out that containers, and specifically by 2014, Docker containers, were a great way to package up a microservice. And as such, Docker appeared at just the right time really – to take advantage of this newfound interest in containers, and to help in the creation of much more scalable applications using a microservice architecture.
Packaging vs Orchestration
But docker didn’t orchestrate. It created a container image. It let you store that image in a registry. It let you pull down that image, and then create a running container from the image. But real-world applications needed quite a few containers running. At least if you were going to design in a microservice-type way.
Docker, the company, quickly saw the need: they were getting customer requests to help solve this orchestration problem. Docker began work on Docker Swarm.
If you weren’t in the middle of containers and cluster orchestration circa 2015 through 2018, you might have missed the storm. There was a lot of competition for mind share during these years for the right way to build an application cluster. And there were many startups producing orchestration products.
Mesos
Mesos, which was introduced in 2009, now governed by the Apache Foundation, is a complete orchestration platform that supports Docker containers. Mesos originated at Berkley11 as an open-source project to build a new type of cluster management. Unlike Kubernetes, Mesos was meant to help handle scaling apps all across the data center, go well beyond just the orchestration of containers.
Mesos spawned a startup, then called Mesophere Inc. A co-founder of Mesos, Benjamin Hindman, was a co-founder of the startup. Mesosphere Inc. received investments from tier one VCs such as Andreessen Horowitz. By 2015 there was news that Microsoft could potentially buy the startup for as much as $1B, but no deal ever surfaced.
Mesosphere built schedulers for Mesos: Marathon and Chronos. These enabled Docker containers to be orchestrated in different ways. Essentially ensuring certain containers were always running in a specific configuration (Marathon) or started and stopped at certain times (Chronos). It’s commercial product DC/OS (Data Center OS), built on Mesos, attracted attention from Internet majors like Twitter, and large solution and cloud operators such as HPE and Microsoft.
As Mesophere was raising a second round, Docker was hard at work on Docker Swarm.
CoreOS
And there were other platforms and startups. Core Inc, which created CoreOS raised their series A back in 2014. CoreOS’s fundamental concept was an “OS as a service.” The idea was to deploy its special version of Linux, and that Linux would auto-update, and it was – to some extent – immutable. You typically would not login to a CoreOS machine. You would configure it and deploy it. And your CoreOS machines would run Docker containers. Core Inc, also made fleet which would tie together CoreOS machines, as a CoreOS cluster, and let you manage what containers they ran together. And they even made their own OCI-compliant runtime – rkt.
OpenShift
Red Hat bought CoreOS in 2018, and quickly RedHat/Fedora-ified things. Fleet and rkt were deprecated. Some of CoreOS technology made it into RedHat OpenShift. Today OpenShift is essentially a paid, commercially supported version of Kubernetes, but with a bunch of extra enterprise features around multi-cloud and role-based access control.
Speaking of OpenShift, OpenShift itself was started with the acquisition of Makara in 2010.12 Makara, built a platform that would help you deploy and scale applications in the cloud.
Docker Swarm Delayed
Coming back to Docker, by 2015 – two years after its first release - the software had established itself as the de-facto standard for Linux containers. In 2013, according to some accounts, Docker was given the opportunity by the Kubernetes team to make it part of the Docker open-source products, with Docker the company being the primary overseer. But the teams could not come to an agreement. So Docker, the company, resolved to push forward with their own Docker Swarm product.13
Kubernetes was in fact the opposite of Docker in many ways. It was complex, not that elegant from the outside (perhaps elegant if you understand its intricacies). But it was industrial grade. And it was complex because its founders had the experience to know all of the edge cases an orchestration platform had to cover to actually work reliably. Swarm was meant to be simple, straightforward and manageable for an organization without a huge DevOps team.
Swarm’s development was delayed. And Docker’s hefty valuation in 2015 put the company under serious pressure to perform. Docker’s entire monetization strategy was based on Swarm. And Swarm’s delays along with the considerable momentum K8s built quickly… the cards were beginning to fall.
Kubernetes, from a marketing and momentum standpoint, entered the market with a lot of advantages. Advantages that may not have been clear to competitors at the time, but today seem obvious.
AWS, Azure and Google Cloud – at the time of Kubernetes release – did not have any kind of serious container orchestration strategy for their cloud users. Companies like Heroku and Makara offered “services” to developers that could “scale” their applications. But these solutions were proprietary and were services – not actual software you could download, customize and use yourself. You had to subscribe to Heroku’s service for instance to deploy your app. And not every large company had faith in their data centers.
Furthermore, these “scale-out services” hid a lot of the backend software you might use, and offered incomplete customization. For instance, what version of MongoDB would be available on the cloud scaler you were going to use?
The Big Guys Adopt K8s
The big 3 hyper-scalers, as we would later refer to them, wanted to sell Cloud – i.e. compute, storage, bandwidth. From a business standpoint, the way a developer would scale their application was less important to them. They simply wanted customers to buy compute instances. And they needed to gain customers faster than each other. By 2013, the race to win at Cloud was on. There was no time to go build more fancy container orchestration concepts.
So, in retrospect, it comes as no surprise that these companies would quickly all get on-board with Kubernetes. It was Apache licensed, they could twist and turn it - make proprietary plugins for it, and they could attempt to steal customers from each other with lower switching costs. So once Google offered Kubernetes, it wasn’t long until Amazon and Microsoft did the same. K8s became the Linux of cluster deployments. It had a permissible license, it was controlled by the corporate collective, everyone had a vested interest, and therefore it was low risk.
Kubernetes: The Linux of Clusters
With the major providers offering K8s solutions, anyone serious about competing had to also. OpenShift, for instance, pivoted to a Kubernetes service in 2015. Mesosphere switched their entire DCOS (Data Center Operating System) to Kubernetes in 2019 and renamed themselves to D2IQ. In platform scenarios like this, it’s a winner-take-all game.
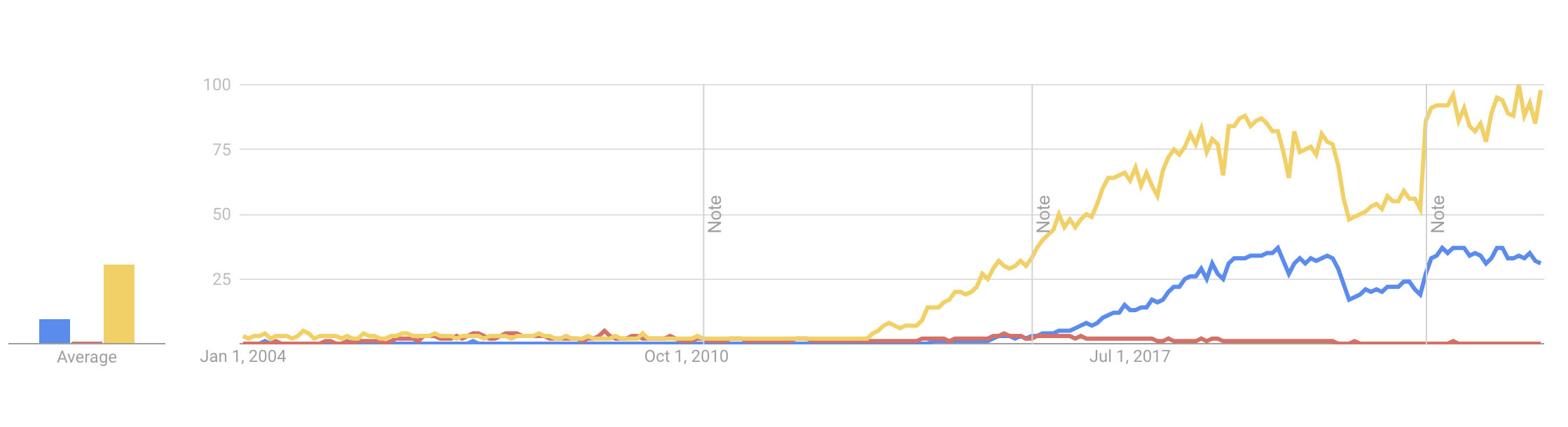
By 2018 Kubernetes commanded the mind share of dev ops and developer’s strategies on cluster deployments and container orchestration. The latest version of Kubernetes does not even have built-in support for docker as a container runtime.
But Docker the tool is still more widely used and understood than Kubernetes. It’s the everyman’s tool for containers. Used for everything from making small tasks simpler to containerizing serious, life-impacting applications in the real world. And DockerCon is still happening - but there is KubeCon now - and it’s bigger. Docker is the tool of choice when building a container, or developing a containerized app; but not when running your apps at scale.
Kubernetes has effectively won the orchestration war. But could Kubernetes have gained this much popularity without Docker? I seriously doubt it. Kubernetes arrived at just the right time: just after everyone understood docker and just before everyone had committed to an orchestration model.
Ed Hemphill
CEO@Izuma Networks
-
https://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf ↩︎
-
https://lwn.net/Articles/199643/ , https://news.ycombinator.com/item?id=25010062 ↩︎
-
https://changelog.com/posts/docker-from-dotcloud-is-now-open-source-the-future-of-linux-containers ↩︎
-
https://www.infoq.com/news/2013/10/dotcloud-renamed-docker/ ↩︎
-
https://www.sramanamitra.com/2015/06/25/billion-dollar-unicorns-containers-gives-docker-entry-into-the-club/ ↩︎
-
https://blog.google/around-the-globe/google-europe/united-kingdom/our-grace-hopper-subsea-cable-has-landed-uk/ ↩︎
-
https://kubernetes.io/blog/2015/04/borg-predecessor-to-kubernetes/ ↩︎
-
https://github.com/kubernetes/kubernetes/blob/release-0.4/README.md (README, release 0.4, 2014) ↩︎
-
https://thenewstack.io/apache-mesos-narrowly-avoids-a-move-to-the-attic-for-now/ ↩︎
-
https://www.infoworld.com/article/3632142/how-docker-broke-in-half.html ↩︎